From distributed monolith to clear boundaries: Redesigning microservices at GetYourGuide
See how GetYourGuide rebuilt its microservices architecture—moving from a distributed monolith to clear, reliable service boundaries. Find out which decisions and strategies now help us deliver features faster and with greater confidence.

Senior Software Engineer

Key takeaways:
We help millions of travelers discover and book unforgettable experiences around the world, with everything from museum tickets to food tours. Behind the scenes, this means our engineering teams must effectively manage availability and pricing for over 200,000 activities.
The problem? Two of our core services had become a distributed monolith: neither could function without the other, data was duplicated across systems, and recovery from issues required coordinating multiple teams. We paused, ran a structured redesign, and rebuilt the boundaries from first principles.
Read on for a detailed breakdown of our process, the five key decisions that changed everything, and what we learned along the way.
{{divider}}
The problem: when services stop being independent
For years, managing availability and pricing was split between two services:
- Inventory handled internally-managed products
- Connectivity handled products integrated with external supplier systems
It seemed logical: different technical requirements, different teams. But over time, this split created problems we couldn’t ignore.
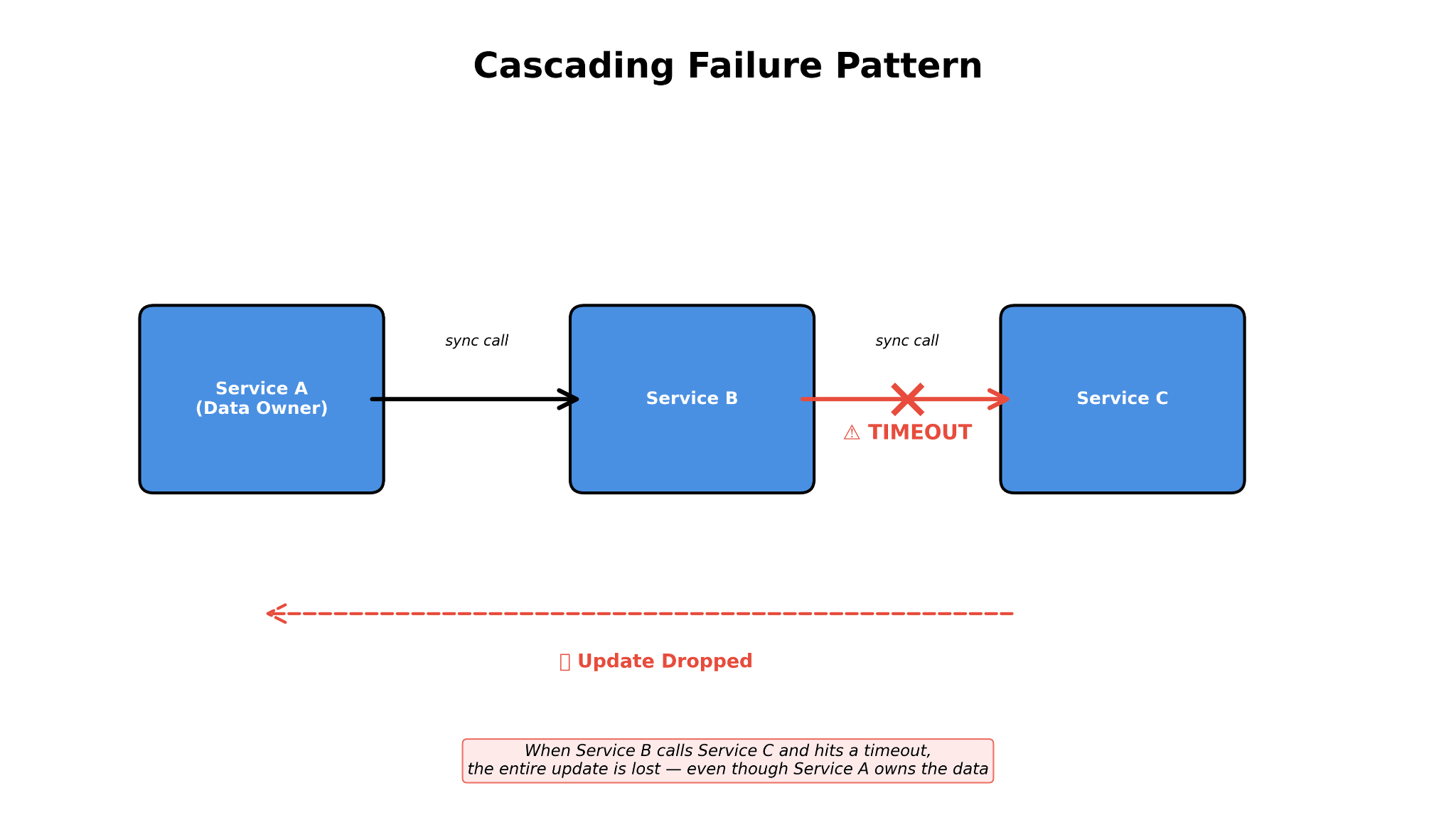
The wake-up call
We started noticing a pattern: operational issues kept pointing to the same place: the seam between these two services.
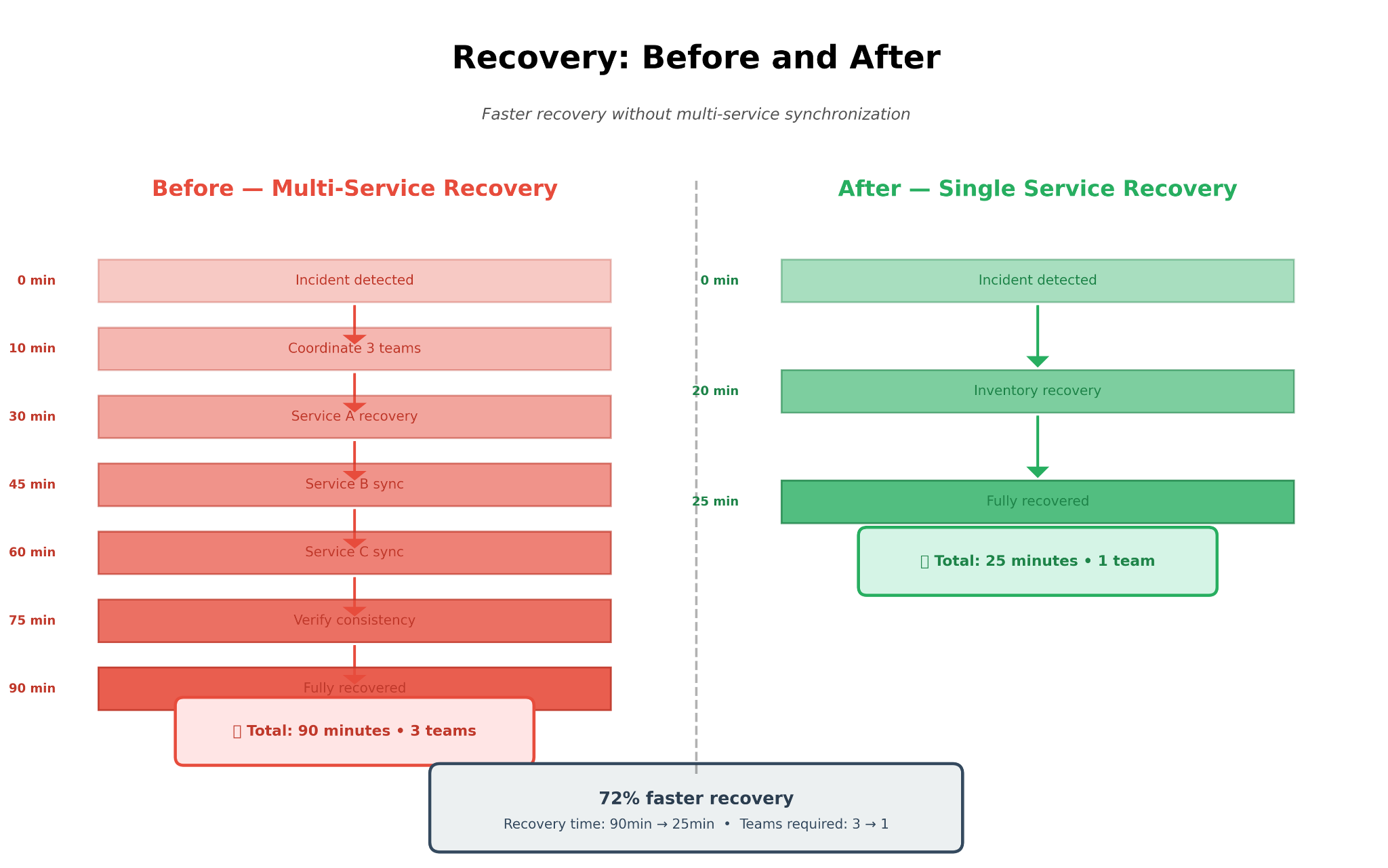
Configuration mismatches between our platform and external systems would silently corrupt data. Changes in one service would cascade into failures in another. And, crucially, recovery required coordinating three different teams and waiting for data to sync across multiple databases.
Our structured approach
Instead of rushing into fixes, we formed a cross-functional team and gave ourselves four weeks to truly understand the problem.
The rule: no sacred rules. Every service boundary, every ownership line, every “but we’ve always done it this way” was on the table.
What we found: four core problems
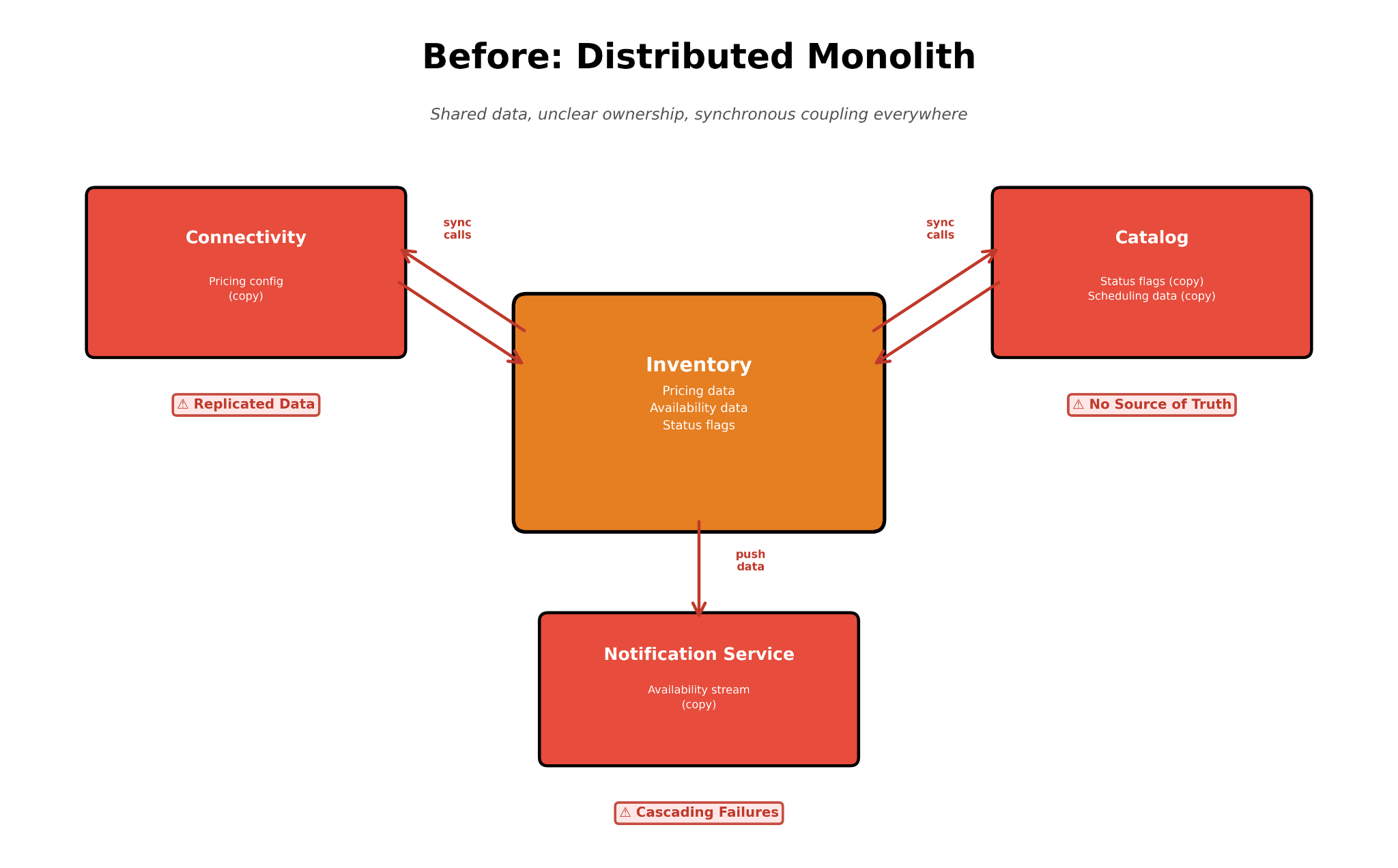
1. A distributed monolith
Core data from one service was quietly duplicated in three others. Each copy seemed harmless, but in total, they meant that a single update had to succeed synchronously across four systems. Any timeout, anywhere, and the entire update failed.
🔍 Deep dive: The anatomy of a distributed monolith
A distributed monolith has all the operational complexity of microservices (network partitions, deployment coordination, distributed tracing) with none of the benefits (independent scaling, isolated failures, team autonomy).
The telltale signs we saw:
1. Bidirectional synchronous dependencies
2. Shared database schemas via replication
3. Cascading deployment risk
The reasoning:
The split began as a sensible modularization: “external integrations have different requirements.” But we drew the boundary around technical implementation (how we fetch data) rather than business capability (what the data represents). Over time, that boundary became a barrier.
The cost:
• Average recovery time: 45 minutes (coordinating three teams)
• Cross-service integration tests: 12-minute feedback cycle
• Deployment coordination overhead: ~2 hours per release
• Operational cognitive load: every on-call engineer needed to understand both systems
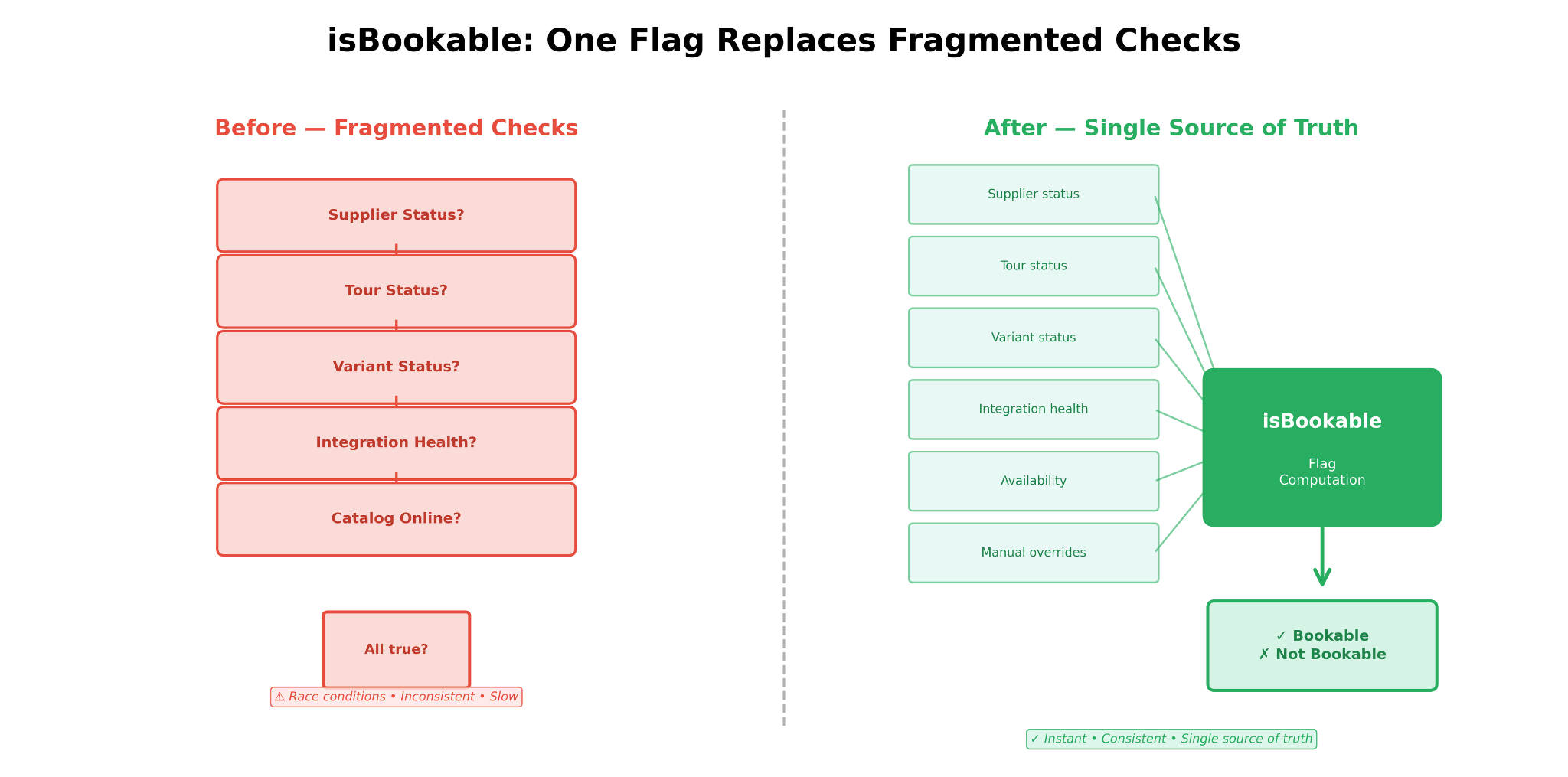
2. No source of truth
During checkout, multiple services each checked their own cached status flags. None was authoritative. They drifted at different rates, so customers could see “available” in search and then hit “sold out” at checkout.
🔍 Deep dive: Implementing the ‘isBookable’ flag
The isBookable flag is conceptually simple, but operationally nuanced. Here’s how we implemented it:
Key design decisions:
1. Eager cache invalidation: Any state change triggers recomputation.
2. GraphQL field resolver: The flag is exposed as a GraphQL field, not a REST endpoint. This lets consumers fetch exactly the fields they need without over-fetching.
3. Audit trail: Every time isBookable transitions from true → false or vice versa, we emit an event with the full state snapshot that caused the change. This makes debugging “why isn’t this bookable?” questions trivial.
4. Performance: Computing the flag on every read would be expensive. Heavy precomputation helps with performance.
3. Wrong boundaries
The entire domain was split by how products were managed (internally vs. externally) rather than what they represented (availability and pricing). A single customer journey crossed two teams, and testing required both codebases. Every issue needed both teams online.
🔍 Deep dive: GraphQL resolution vs. data replication
Replacing asynchronous data replication with synchronous GraphQL resolution sounds risky. We asked, “Won’t this make everything slower and more fragile?” The surprising answer: no.
Why it works:
1. GraphQL has built-in batching: DataLoader batches multiple requests into a single database query, avoiding N+1 problems.
2. Inventory is already highly available: 4 nines SLA, backed by read replicas. Adding Catalog as a consumer doesn’t meaningfully change its load profile.
The trade-off:
We gave up fire-and-forget async writes and accepted sync reads with fallback. For our domain, that’s the right trade:
• Availability data changes infrequently (median: once per day per tour)
• Staleness confuses customers (“Why did availability disappear during checkout?”)
• Operational simplicity (no Kafka lag, no consumer monitoring) is worth 40ms
When replication still makes sense:
We didn’t eliminate all replication. We still replicate:
• Analytics events (high volume, non-critical, async is perfect)
• Audit logs (write-heavy, read-rarely, async is cheaper)
• Search index updates (Elasticsearch can’t resolve GraphQL, needs pushed data)
The principle: replicate when the consumer can’t afford to wait or can tolerate staleness. Otherwise, resolve on reads.
4. Invisible side effects
Database triggers fired on commits. External systems could silently rewrite the configuration. A single API call handled six different responsibilities. Debugging meant tracing invisible dependencies.
🔍 Deep Dive: The Event-Driven Refactor
Replacing database triggers with explicit events was harder than we expected, and more valuable.
The old way: invisible side effects
This trigger:
• Fires synchronously in the same transaction
• Has no visibility in application logs
• Can’t be unit-tested without a database
• Doesn’t emit metrics
When a supplier deactivation took 40 seconds, we had no idea why until we combed through database logs and found the trigger was updating 12,000 tour records in a loop.
The new way: explicit events
Then, in a separate event handler:
Benefits:
1. Observability — Every event is logged, traced, and counted in metrics
2. Testability — Event handlers are plain Java classes; mock the publisher and assert on emitted events
3. Debuggability — Event logs show the full cascade: “SupplierDeactivated → 47 TourDeactivated events”
4. Replay-ability — Re-run the handler against production events in a staging environment
Performance impact:
Triggers were synchronous and fast (sub-millisecond). Events are asynchronous and slower (10–50ms to publish to Kafka).
But the total transaction time dropped because the heavy cascade work moved out of the critical transaction:
• Before: 40-second transaction (blocking writes to suppliers table)
• After: 120ms transaction + 30 seconds of async event processing (non-blocking)
When triggers still make sense:
We kept a few triggers for:
• Audit columns (updated_at, updated_by): low complexity, universal
• Referential integrity (soft deletes via triggers): too risky to refactor
The principle: triggers are fine for local, deterministic, low-complexity side effects. For anything business-critical or cross-table, we use events.
The redesign: five key decisions
Instead of rewriting everything, we identified five architectural changes that would fix the root causes.
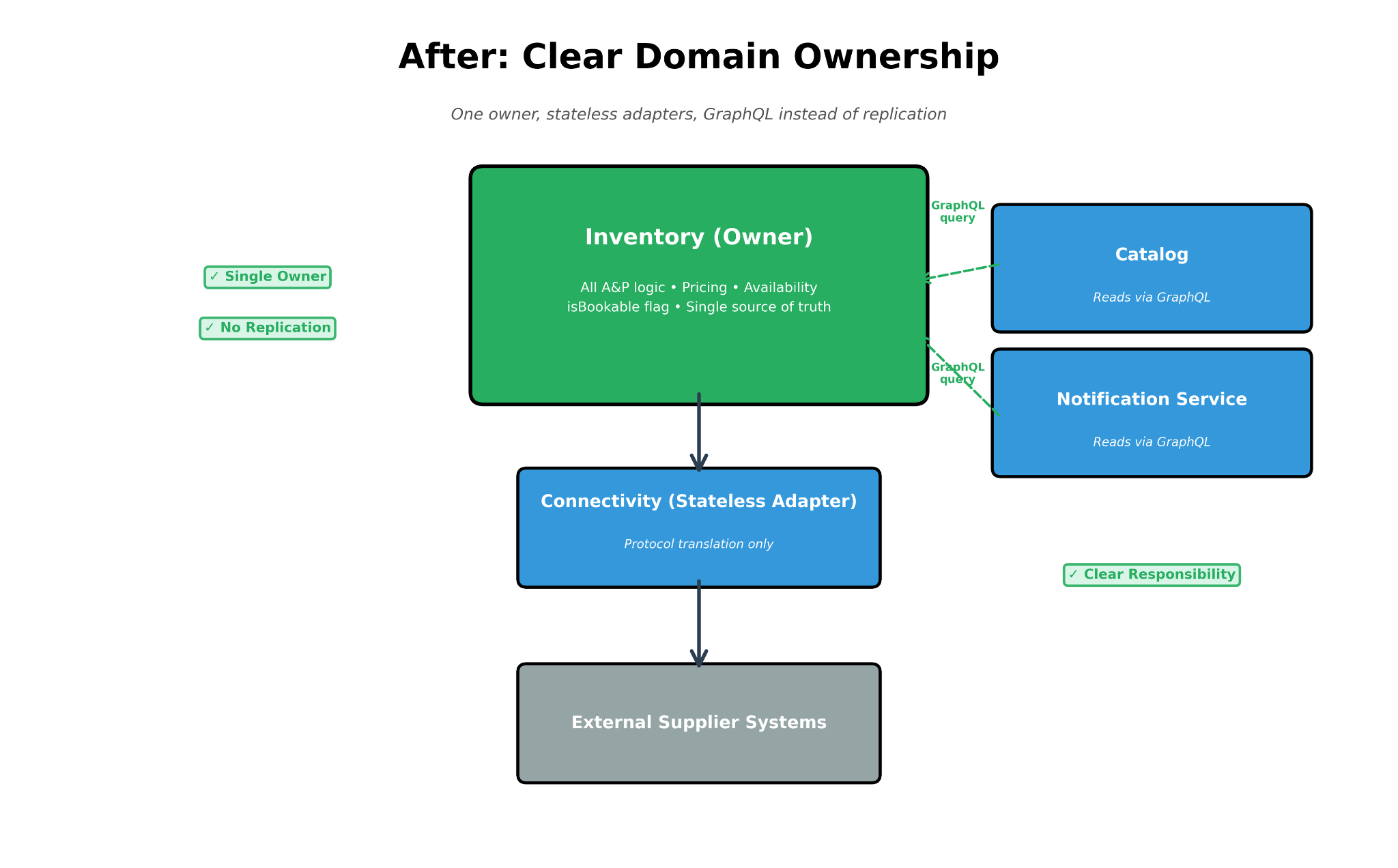
Decision 1: One service owns the entire domain
All availability and pricing logic, regardless of how it’s managed, moves into Inventory. Connectivity becomes a pure adapter: it translates protocols, no business logic or stored state.
Benefit: One team, one codebase, one place to test and debug.
Decision 2: A single source of truth
Instead of each service checking its own cached flags:
The isBookable flag is computed from supplier status, product status, integration health, availability, and manual overrides. Everyone else just reads it.
Benefit: Checkout depends on one service. Recovery is instant, with no need to wait for syncs.
Decision 3: GraphQL instead of replication
Other services stop receiving pushed copies of data. They query for what they need, when they need it, through GraphQL resolvers.
Benefit: Real-time consistency. No background sync jobs. No stale data.
Decision 4: Explicit events
We replaced database triggers with named, versioned events: supplier_activated, product_deactivated, and availability_updated. Side effects become visible, testable, and traceable.
Benefit: Clear cause-and-effect. Events can be monitored, replayed, and debugged.
Decision 5: No silent mutations
External systems can no longer silently rewrite settings. A mismatch either rejects the payload with a clear error or deactivates the product loudly, triggering an alert and an audit trail.
Benefit: Configuration changes are traceable and require human review.
Early results
At the time of writing (May 2026), we’re mid-redesign, but the changes are already visible:
- Faster recovery: Bringing the domain online no longer requires waiting for other services to sync.
- Clearer ownership: When something breaks, the team that owns it fixes it.
- Simpler deployments: Teams ship features without coordinating across repos.
🔍 Deep dive: Migration risk management
A redesign of core domain services is a high-stakes migration. We couldn’t afford a “big bang” cutover. Here’s how we de-risked it.
1. Parallel run (shadow mode)
Every major change ran in shadow mode first:
• Old logic remained the source of truth
• New logic ran in parallel (via feature flag)
• We logged every divergence with full context
• Metrics tracked mismatch rate
Example: When we introduced isBookable, we ran both the old distributed check and the new flag computation for every checkout request. A mismatch triggered a detailed log:
We investigated every mismatch. Turned out the old logic was reading stale integration health from a replicated table; the new logic was reading fresh from Inventory’s source table. The mismatch proved the new logic was more correct.
2. Feature flags with gradual rollout
We used our own experimentation platform for gradual rollout:
• Week 1: 1% of traffic (internal employees only)
• Week 2: 5% of traffic
• Week 3: 25% of traffic
• Week 4: 50% of traffic
• Week 5: 100% of traffic
At each step, we monitored:
• Error rates (compared to the control group)
• Latency (p50, p99, p99.9)
• Booking conversion rate (the ultimate metric)
Any regression > 1% triggered an automatic rollback.
3. Rollback plan for every release
Every project had a documented rollback plan:
Change: Introduce isBookable flag
Rollback Strategy: Feature flag off
Rollback Time: 30 seconds
Change: Delete replicated pricing table
Rollback Strategy: Restore from snapshot, re-enable replication
Rollback Time: 15 minutes
Change: Remove database triggers
Rollback Strategy: Re-run migration script, re-enable triggers
Rollback Time: 10 minutes
We practiced rollbacks in staging. Twice we had to use them in production (once due to a bad deploy, once due to an unexpected load spike). Both times, recovery took < 5 minutes.
Results:
10 projects, 18 production releases, zero customer-facing incidents, zero rollbacks due to correctness bugs. The shadow mode and gradual rollout caught everything before it hit customers.
What we learned
Sometimes you have to stop shipping to keep shipping. The pressure to deliver features makes architectural work feel indulgent. It’s not. A month of research saved us quarters of firefighting.
Wrong boundaries compound over time. The split made sense when we made it. But as the business grew, the cost grew exponentially.
Data replication is a trap. It starts as “just a cache.” It ends as a critical dependency you can’t remove.
Implicit behavior is the enemy of reliability. Triggers, side effects, and silent mutations make debugging nearly impossible.
Architecture enables testing. You can’t write good tests for a domain that spans three services with unclear boundaries. Fix the architecture, and tests become easier.
Facing something similar?
Here are some of the warning signs worth taking seriously:
- Issues keep pointing to the same pair of services
- Recovery requires multiple teams
- “It’s complicated” is the honest answer to “how does this work?”
- Tests mock three or more services
- Features touch multiple repos
If that sounds familiar, here’s what worked for us:
- Get explicit buy-in for time without feature pressure
- Form the team across organizational lines, not within one team
- Anchor every problem to real operational pain to keep the work honest
- Document as you go by sequencing diagrams and keeping decision records
- Break the design into shippable chunks — every step should deliver value
In conclusion
Redesigning core systems doesn’t ship customer features. It’s hard to celebrate and even harder to justify. But the alternative (accumulating architectural debt) is worse. Every cross-service dependency slows down the next feature.
We chose the long game: not a complete rewrite, but a deliberate, researched redesign with a clear migration path. Looking ahead six months, we’ll be shipping faster, on simpler systems, with clearer ownership.
Want to work alongside a growing, cooperative tech and change the way the world travels? Check out our open tech roles.

More articles like this







